

宝博体育,宝博,宝博体育官网,宝博app下载,宝博体育网址,宝博体育官方网站,宝博体育注册,宝博体育靠谱吗,宝博体育登录,宝博体育入口,宝博体育注册,宝博官方网站,宝博APP,宝博注册,宝博网址(本网页是第12章内容,全书内容请点击这里访问本书官网,官网提供本书整本电子书PDF下载)
文献[DebnathSL10]中列举了键值存储的两个重要的实际应用领域:多人游戏和重复数据删除。
(1)多人游戏:目前网络在线多人游戏产业非常繁荣,吸引了大量的玩家。多人游戏中,要求处于不同地理位置的多个玩家,能够及时交互信息,这就需要服务器能够及时获得、存储和处理各个玩家的游戏状态信息。为了保证这些玩家信息处理的实时性,就要求存储这些数据的存储设备具有很高的访问速度。传统的磁盘的读写延迟比较高,无法有效满足这种需求,速度较快的RAM产品价格太高,无法大量使用。因此,性价比较高的闪存,就成为可以满足这类应用需求的首选产品。
(2)重复数据删除:在云存储时代,百度网盘等云存储产品越来越受到网民的欢迎,每天都有大量的用户把相关数据传输到云存储中。另外,对于企业而言,为了保证数据的可用性和可靠性,也都建立了数据备份制度。无论是个人用户数据还是企业用户数据,都可能存在重复存储的可能。在当今数据大爆炸的时代,重复数据删除的作用就尤为凸显,可以帮助企业减少重复数据存储,节约存储空间,降低企业开销。重复数据删除的方法就是,把文件分成多个块,然后对每个块使用SHA-1哈希,从而判定两个块是否包含相同的数据。为了加快速度,一般都是放在RAM中运行重复数据删除算法。但是,随着数据的暴增,RAM有限的空间已经无法容纳如此多的数据,因此,就必须把数据保存到磁盘上,通过建立索引来快速获取磁盘中的数据。但是,磁盘的读写延迟较大,因此,如果采用性价比高的闪存来替代磁盘的角色,可以获得更好的重复数据删除性能。
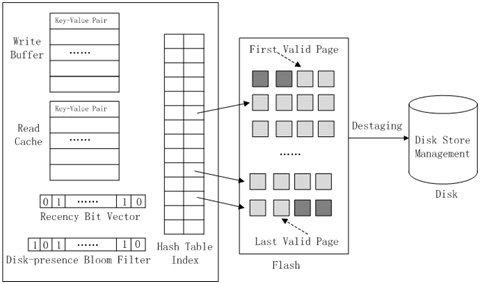
FlashStore[DebnathSL10]在闪存中以日志结构的方式来存储“键值对”,从而可以充分获得更好的顺序写性能。同时,采用常驻内存的哈希表来为这些“键值对”提供索引,当哈希表出现冲突时,采用一种“布谷鸟哈希”的变体来解决冲突。如图[FlashStore]所示,FlashStore包含了如下组件:
(1)RAM写缓冲区:所有更新操作都首先进入缓冲区保存,只有缓冲区的数据量可以正好填满一个闪存页时,才一次性把缓冲区的数据刷新到闪存中。
(2)RAM哈希表索引:这是为闪存中所存储的“键值对”建立的索引,通过这个索引,只需要一次闪存读操作,就可以获得闪存中的数据。采用了一种“布谷鸟哈希”的变体来解决哈希表冲突。
(3)RAM读缓存:保存最近读取过的“键值对”,并且采用最近最少使用策略进行替换。
(5)布隆过滤器[BroderM02]:用来判断一个“键值对”是否已经被保存到磁盘中。
(6)闪存:用来存储经常使用的“键值对”,闪存页被组织成循环链表的形式,系统会周期性地执行“回收”过程,从链表中回收无效页和不经常使用的页(这时会用到近期位向量)。
(7)磁盘:从闪存中驱逐出来的“键值对”会被保存到磁盘中,一般都是不常用的数据。
FlashStore采用了布隆过滤器来提升读写过程的速度,因此,这里简单介绍一下布隆过滤器的原理。布隆过滤器[BaiduBaike]是由布隆在1970年提出的,它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中,它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率。布隆过滤器采用的是哈希函数的方法,将一个元素映射到一个长度为m的阵列上的一个点,当这个点是 1 时,那么这个元素在集合内,反之则不在集合内。这个方法的缺点是,当检测的元素很多的时候可能有冲突,解决方法就是使用k个哈希函数对应k个点,如果所有点都是 1 的话,那么元素在集合内,如果有 0 的话,则判断元素不在集合内。
(1)读操作过程:当使用一个键去读取数据时,首先到RAM读缓存中查找,如果找不到,就继续到RAM写缓冲区去查找,如果还是找不到,就查找RAM哈希表索引,如果仍然找不到,就利用布隆过滤器来判断这个键是否存在于磁盘中,如果布隆过滤器判断为存在,则到磁盘中寻找该键,如果判断为不存在,则返回空值。在上述过程中,如果在RAM读缓存之外的其他地方找到了该键,就把该键更新到RAM读缓存中,同时也会发生“近期位向量”的更新,从而记录最近被访问过的哈希表索引条目。
(2)写操作过程:首先把一个“键值对”写入到RAM写缓冲区,如果缓冲区中已经存在一个旧版本的数据,就让旧版本失效。如果发现缓冲区已满一页,就把数据刷新到闪存中,并更新RAM哈希表索引。
FlashStore的缺点是:(1)使用变种的布谷鸟哈希函数时,需要人为设定所使用的哈希函数的数目,这个值不同,所取得的性能也不同,而对于不同的负载类型,键值分布区间不同,为达到最好性能所需要设定的哈希函数的数目也是不同的。(2)随着键的数量的增加,布隆过滤器的误识别率也会增加,这是个不容忽视的问题。
下面进一步分析一下布隆过滤器的特性对于FlashStore的性能影响。对于布隆过滤器而言,在采用多个哈希函数时,如果至少有一个函数判断元素不在集合中,那肯定就不在。如果它们都说元素在集合中,却有一定的误判概率,也就是说实际上元素可能并不存在。这个特性对FlashStore有着很大的影响。
下面我们分析四种不同的读写操作情形。对于FlashStore的读操作而言,存在下面两种情形:
(1)情形一:如果布隆过滤器判断某个键不存在于磁盘中时,这个键就一定不会已经保存在磁盘中,所以返回空值;如果不采用布隆过滤器,就必须到磁盘进行查找,所以,在这种情形下,布隆过滤器可以帮助节省搜索磁盘的开销;
(2)情形二:如果布隆过滤器判断某个键存在于磁盘中,这个键未必真的已经保存在磁盘中,可能是误判。不过,不管是否误判,FlashStore都会到磁盘中去找这个键,如果找不到该键,就返回空值,如果找到了,就返回键值对。所以,在这种情形下,布隆过滤器不仅没有节省开销,而且增加了一个判断过程的开销。
(1)情形三:如果布隆过滤器判断某个键不存在于磁盘中时,这个键就一定不会已经保存在磁盘中,所以,写操作必须把该键值对写入到磁盘中。如果不采用布隆过滤器,就必须先到磁盘查找该键是否存在,如果不存在就写入磁盘。可以看出,采用布隆过滤器以后,可以节省磁盘查找的开销。
(2)情形四:如果布隆过滤器判断某个键存在于磁盘中,这个键未必真的已经保存在磁盘中,可能是误判。不过,不管是否误判,FlashStore都会到磁盘中去找这个键,如果找不到该键,就写入磁盘,如果找到了,就不执行写操作。可以看出,采用过滤器以后,不仅没有节省开销,而且增加了判断过程的开销。
从上面的四种情形的讨论可以看出,情形一和情形三可以节省开销,而情形二和情形四则会增加开销。因此,FlashStore要想取得好的性能,必须保证情形一和情形三所节省开销,一定要大于情形二和情形四所增加的开销。也就是说,当布隆过滤器判断不存在的情形较多时,FlashStore收益会比较大。但是,从作者给出的大量实验结果来看,并没有关于这个方面的详细分析。
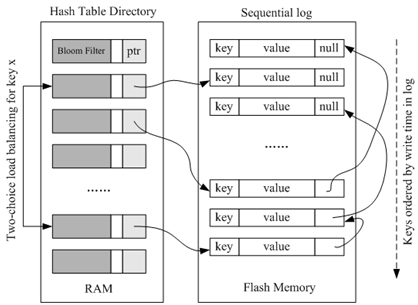
文献[DebnathSL11]提出了一个基于闪存的键值存储——SkimpyStash,只需要占用很少的RAM空间。如图[SkimpyStash]所示,SkimpyStash在RAM中使用了一个哈希表目录来索引“键值对”,而这些键值对是以日志结构的方式存储在闪存上的。为了确定每个键值对在闪存中的位置,需要为每个键值对设置闪存指针,这会带来大量的RAM空间开销,为了解决这个问题,作者采用如下的方法:(1)使用线性链表解决哈希表冲突,即当有多个键被映射到同一个哈希桶中时,就会被组织成一个链表;(2)把链表存储到闪存上,并且在每个哈希桶中存储一个指向链表头部的指针。
使用哈希函数把键分配到各个哈希桶中,可能会导致每个桶中包含的键的数量不同,有时候甚至有很大的扭曲分布,这就会使得部分哈希桶对应的链表长度过大,增加了平均查找时间。为了让每个哈希桶尽量包含相近数量的键,从而减少与其对应的链表的长度,加快查找速度,作者采用了基于双选的负载均衡策略[Azar94],该策略最初是用于把多个球均匀地投入到不同的箱子中。“双选”策略的基本思想是:每个键都使用两个不同的哈希函数f1和f2,产生两个候选的哈希桶,然后,把该键放入到元素个数较少的那个哈希桶中。
但是,在采用双选策略后,又会增加查找过程的闪存读操作次数。因为,现在每个键都有两个可能存放的哈希桶,在查找时,如果在第一个哈希桶中找不到,就要再到第二个哈希桶中查找。在最坏的情况下,闪存读操作的次数会翻倍。为了解决查找延迟的问题,作者进一步采用了布隆过滤器(Bloom Filter)。
采用布隆过滤器以后,针对某个键的读操作过程如下:使用两个不同哈希函数找到该键可能存在于其中的两个不同的候选桶,布隆过滤器判断认为该键在哪个桶中,则到该桶指向的哈希链表中继续寻找该键。但是,布隆过去器有一定的误识别率,即当它判断认为该键存在于某个哈希桶中时,实际上可能并不存在,这意味着,扫描一遍该桶对应的哈希链表以后,却找不到该键,浪费了查找时间。幸运的是,文献[DebnathSL11]通过大量实验显示,这种误识别率不会超过2%。因此,采用布隆过滤器总体上加快了键的平均查找速度。
SkimpyStash的缺点是:由于采用布隆过滤器判定一个键是否存在于某个哈希桶中,因此,不可避免地继承了布隆过滤器的缺点,即随着存入哈希桶的元素数量的不断增加,误识别率也会随之增加。
[Xiang09] 向小岩. 闪存数据库若干关键问题研究. 博士学位论文. 中国科技大学. 2009.
[LvCC09]吕雁飞,陈学轩,崔斌.基于闪存的数据库性能评测与优化分析.计算机研究与发展.46(增):307-312,2009.
[YueXJL10] 岳丽华,向小岩,金培权,刘沾沾.基于分离日志的闪存数据库系统存储管理方法.中国科学技术大学学报.Vol.40(5), 2010:526-532.